태블로 자동화 가능한가요 !
네 가능합니다!! 유로 버젼만 가능하고 유료 버젼에서 쓸 수 있는 태블로 서버랑 파이썬 라이브러리를 API 로 연결해서 할 수 있어요! 이걸로 반복문을 돌릴 수 있게 되었습니다 우리는.. 데이터를 리프레쉬해서 만드는것도 되구요 저처럼 pdf 추출 자동화도 가능함!
그런데 한국어로 된 이걸 잘 설명해주는 문서가 없어서 제가 씁니다...
태블로 이시키들 한국 지사를 안 가지고 있어요 ㅠ ㅠ
salesforce 한국쪽에다가 전화하면 영업팀만 받고 기술지원팀은 나몰라라야
뭔가 궁금한거 물어보려면 일본 지사 사람이랑 컨택해야돼 (근데 한국인 담당자가 있음)
저는 유료판 구매에서 라이선스부터 애를 먹고 태블로 측과 많은 멜을 주고 받았어요
하지만 도움이 되지는 않았답니다 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
결국은 그냥 멋진 외국 유튜버들이 올려둔 외부 라이브러리 쓰는 법을 한 번 더 한국어로 정리해서 올려두려구 블로그를 켰어요.. 그래서 오늘 쓸 API 메서드는 태블로 공식문서에 나와있는 방법이랑은 약간 다른 방법입니다.
우선 태블로 cloud (혹은 태블로 online) 에 들어가자. 들어가자마자 상단에 있는 url 이 중요한데, 나중에 저 url 이 고유값으로 역할한다. 이따가는 내걸 보여줄 순 없기 때문에 가상의 url 로 바꿔서 예시를 보여드리겠음
그리고 프로필 > 내 계정 설정으로 들어가서 아래로 쭉 내리면
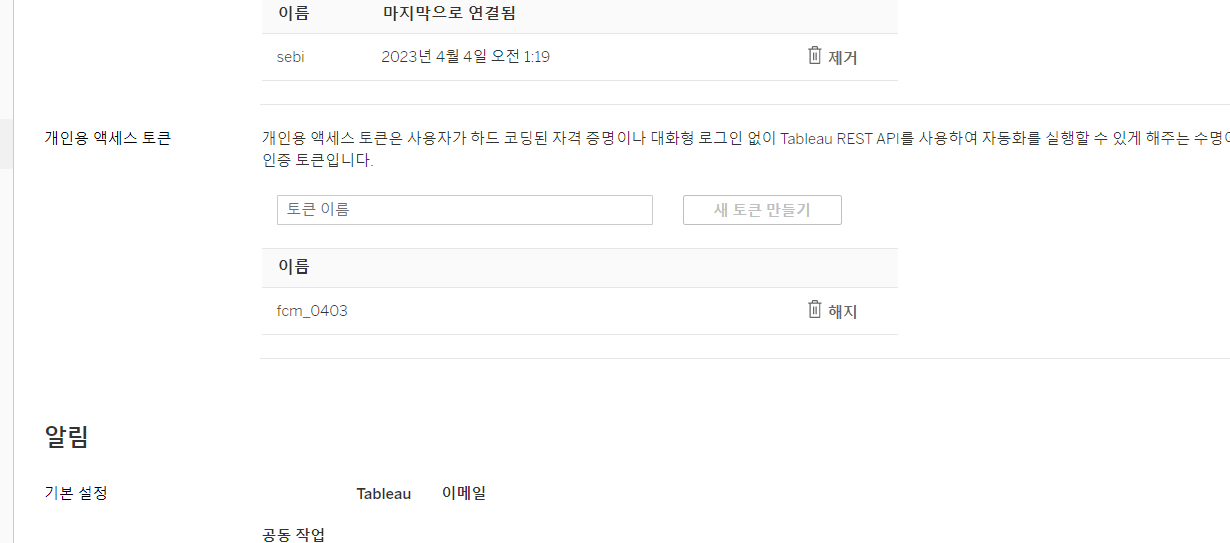
이렇게 개인용 엑세스 토큰을 발급받는 곳이 보인다
여기서 새 토큰 만들기를 눌러 발급받고 코드는 잘 복붙해 두면 된다.
그러면 이제 준비는 끝났다.
이번 포스팅에서 쓸 라이브러리는 tableau_api_lib 라는 라이브러리다. 내가 참고한 유튜브 영상의 멋진 아재가 만들어둔 멋진 라이브러리.. 당신 덕분에 제가 수작업을 안 해도 되었어요... 감사합니다..
라이브러리 문서: https://pypi.org/project/tableau-api-lib/
tableau-api-lib
This library enables developers to call any method seen in Tableau Server's REST API documentation.
pypi.org
파이썬에서 라이브러리를 임포트해주자
pip install tableau_api_lib
from urllib import parse
from tableau_api_lib import TableauServerConnection
from tableau_api_lib.utils import querying, flatten_dict_column
그리고 나서는 이제 인증 정보를 담을 config json 파일을 작성해야 한다
복붙해서 쓰세요
config = {
'tableau_prod': {
'server': 'http://nuci5server/',
'api_version': '3.12',
# 'username': '<YOUR_PROD_USERNAME>',
# 'password': '<YOUR_PROD_PASSWORD>',
'personal_access_token_name': 'test_token_local',
'personal_access_token_secret': 'dz6zY5TJRuusIclY0UnBkg==:dPMRK8VUa60vKVjxuHudA8YGigtziGzd',
'site_name': '',
'site_url': ''
}
}
이때 들어가는 파라미터들은 다음과 같이 채우면 된다
아까 언급한 태블로 클라우드의 초기 url 이 만약에 이렇게 뜬다면
'https://lalala-something-a.online.tableau.com/#/site/thisissitename/home'
config json 은 다음과 같이 입력해야 함
config = {
'tableau_prod': {
'server': 'lalala-something-a.online.tableau.com/',
'api_version': '3.19',
'personal_access_token_name': '토큰이름',
'personal_access_token_secret': '토큰',
'site_name': 'thisisitename',
'site_url': 'thisisitename'
}
}
이것도 23년 4월 기준인데, api 버젼은 서버 버젼보다 낮으면 안되니, 경고 문구가 뜨면 버젼업을 해주도록 하자. 또 나의 예시처럼 토큰 이름과 토큰으로 인증하고 들어가는 방법이 있고, 토큰 없이 아이디랑 패스워드 치고 들어가는 방법도 있다고 한다. (그럼 애초부터 왜 토큰을 발급받아야 하는건지 이해불가...)
이제는 메서드들을 이용해 본격적으로 자동화를 시켜보자. 나의 task 는 다음과 같다
1. 내가 가진 대시보드 4개의 필터 200개를 돌려 pdf 로 다운받기
2. 대시보드의 항목 중 null 값이 있는 경우에는 pdf 생성에서 제외시키기
3. 만들어진 네 개의 pdf 를 합치고
4. 4월보고서_필터이름 이라는 조건으로 이름을 지정해 저장하기
1. 서버에 연결하기
이 코드를 이용하면 연결이 가능하다
Response 200 이 뜨면 연결이 잘 됐다는 뜻이다
conn = TableauServerConnection(config_json=config, env='tableau_prod')
conn.sign_in()
2. 대시보드 정보 (id) 가져오기
겟 뷰를 이용해서 대시보드 정보를 가져올 수 있다. (정보 보안 문제로 보여주긴 어려우나) 가져온 데이터프레임의 'id' 컬럼에 들어와있는 아이가 각 대시보드의 고유 id 가 된다. 뒤에서 쓸거니 잘 메모해두자
views_df = querying.get_views_dataframe(conn)
views_df.tail()
3. id 를 이용해 필터링하기
3.1. 가지고 올 대시보드 아이디를 지정한다
3.2. 반복문으로 돌릴 리스트를 만들고, 저장경로를 지정한다
3.3. 필터 이름과 필터에 들어갈 value 를 파싱해준다. 이때! 필터 이름이 너무 길고 한국어로 되어있으면 파싱값이 지저분하게 나오고, 에러날 확률이 올라감. 참고!!
3.4. 파라미터를 지정해준다. 레이아웃 뷰랑 아까 파싱한 필터를 지정하면 된다.
3.5. response 값이 200인 경우만 (에러가 아닌 경우만) pdf 로 추출한다
#가지고 올 대시보드 아이디
pdf_view_id = 'put your dashboard id'
#반복문으로 돌아갈 항목 리스트
li = df['user_nickname'].tolist()
#저장경로지정
output_dir = '/content/drive/MyDrive/somewheref'
#필터링 할 대상 지정
import urllib
import os
for i in li:
#파싱
#url_friendly 하게 입력값을 바꿔주는것임
filter_name = urllib.parse.quote("Nickname")
filter_value = urllib.parse.quote(i)
#필터링 지정
pdf_params = {
"pdf_orientation":"orientation=Landscape",
"pdf_layout":"type=A4",
"name_filter": f"vf_{filter_name}={filter_value}",
}
zero_pdf = conn.query_view_pdf(view_id = pdf_view_id , parameter_dict= pdf_params)
if zero_pdf.status_code == 200:
output_filename = f"0.{i}.pdf"
output_path = os.path.join(output_dir, output_filename)
with open(output_path, 'wb') as file:
file.write(zero_pdf.content)
else:
print(f"{i} 누락")
나의 경우에는 일단 따로따로 항목별로 저장해 준 뒤 합쳤다
이중포문을 쓰니 에러가 심했음...
4. pdf 로 합치기
pdf merger 를 이용했다.
버젼때문에 오류가 잦음...
이부분은 지피티의 도움을 받았음.
from PyPDF2 import PdfReader, PdfMerger
import os
output_dir = 'something'
# Loop through the image pairs
# Open the two images for this pair
pdf1 = open(f'something {i}).pdf', 'rb')
pdf2 = open(f'something {i}).pdf', 'rb')
pdf3 = open(f'something {i}).pdf', 'rb')
# Create a PDF merger object
pdf_merger = PdfMerger()
# Add the three PDF files to the merger object
pdf_merger.append(PdfReader(pdf1))
pdf_merger.append(PdfReader(pdf2))
pdf_merger.append(PdfReader(pdf3))
# Get the user name for the current image pair
for name, number in user_dict.items():
if str(number) == str(i):
user_name = name
break
# Construct the output filename
output_filename = f'_유저분석보고서_{user_name}.pdf'
pdf_merger.write(os.path.join(output_dir, output_filename))
참조
https://www.youtube.com/watch?v=b8QElp-qV7w&t=870s
https://www.youtube.com/watch?v=yYo-TyqG_Ks
'데이터 분석 Data Analysis > Tableau' 카테고리의 다른 글
| [태블로] 태블로 월별로 여러 데이터셋 집계하기 (0) | 2023.09.03 |
|---|---|
| [태블로] 태블로 데이터 refresh 하는 법 3가지 (0) | 2023.08.31 |
| [태블로] 태블로 날짜 월별로 예쁘게 나타내기 (jan, feb, mar...) (0) | 2023.08.21 |
태블로 자동화 가능한가요 !
네 가능합니다!! 유로 버젼만 가능하고 유료 버젼에서 쓸 수 있는 태블로 서버랑 파이썬 라이브러리를 API 로 연결해서 할 수 있어요! 이걸로 반복문을 돌릴 수 있게 되었습니다 우리는.. 데이터를 리프레쉬해서 만드는것도 되구요 저처럼 pdf 추출 자동화도 가능함!
그런데 한국어로 된 이걸 잘 설명해주는 문서가 없어서 제가 씁니다...
태블로 이시키들 한국 지사를 안 가지고 있어요 ㅠ ㅠ
salesforce 한국쪽에다가 전화하면 영업팀만 받고 기술지원팀은 나몰라라야
뭔가 궁금한거 물어보려면 일본 지사 사람이랑 컨택해야돼 (근데 한국인 담당자가 있음)
저는 유료판 구매에서 라이선스부터 애를 먹고 태블로 측과 많은 멜을 주고 받았어요
하지만 도움이 되지는 않았답니다 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
결국은 그냥 멋진 외국 유튜버들이 올려둔 외부 라이브러리 쓰는 법을 한 번 더 한국어로 정리해서 올려두려구 블로그를 켰어요.. 그래서 오늘 쓸 API 메서드는 태블로 공식문서에 나와있는 방법이랑은 약간 다른 방법입니다.
우선 태블로 cloud (혹은 태블로 online) 에 들어가자. 들어가자마자 상단에 있는 url 이 중요한데, 나중에 저 url 이 고유값으로 역할한다. 이따가는 내걸 보여줄 순 없기 때문에 가상의 url 로 바꿔서 예시를 보여드리겠음
그리고 프로필 > 내 계정 설정으로 들어가서 아래로 쭉 내리면
이렇게 개인용 엑세스 토큰을 발급받는 곳이 보인다
여기서 새 토큰 만들기를 눌러 발급받고 코드는 잘 복붙해 두면 된다.
그러면 이제 준비는 끝났다.
이번 포스팅에서 쓸 라이브러리는 tableau_api_lib 라는 라이브러리다. 내가 참고한 유튜브 영상의 멋진 아재가 만들어둔 멋진 라이브러리.. 당신 덕분에 제가 수작업을 안 해도 되었어요... 감사합니다..
라이브러리 문서: https://pypi.org/project/tableau-api-lib/
tableau-api-lib
This library enables developers to call any method seen in Tableau Server's REST API documentation.
pypi.org
파이썬에서 라이브러리를 임포트해주자
pip install tableau_api_lib
from urllib import parse
from tableau_api_lib import TableauServerConnection
from tableau_api_lib.utils import querying, flatten_dict_column
그리고 나서는 이제 인증 정보를 담을 config json 파일을 작성해야 한다
복붙해서 쓰세요
config = {
'tableau_prod': {
'server': 'http://nuci5server/',
'api_version': '3.12',
# 'username': '<YOUR_PROD_USERNAME>',
# 'password': '<YOUR_PROD_PASSWORD>',
'personal_access_token_name': 'test_token_local',
'personal_access_token_secret': 'dz6zY5TJRuusIclY0UnBkg==:dPMRK8VUa60vKVjxuHudA8YGigtziGzd',
'site_name': '',
'site_url': ''
}
}
이때 들어가는 파라미터들은 다음과 같이 채우면 된다
아까 언급한 태블로 클라우드의 초기 url 이 만약에 이렇게 뜬다면
'https://lalala-something-a.online.tableau.com/#/site/thisissitename/home'
config json 은 다음과 같이 입력해야 함
config = {
'tableau_prod': {
'server': 'lalala-something-a.online.tableau.com/',
'api_version': '3.19',
'personal_access_token_name': '토큰이름',
'personal_access_token_secret': '토큰',
'site_name': 'thisisitename',
'site_url': 'thisisitename'
}
}
이것도 23년 4월 기준인데, api 버젼은 서버 버젼보다 낮으면 안되니, 경고 문구가 뜨면 버젼업을 해주도록 하자. 또 나의 예시처럼 토큰 이름과 토큰으로 인증하고 들어가는 방법이 있고, 토큰 없이 아이디랑 패스워드 치고 들어가는 방법도 있다고 한다. (그럼 애초부터 왜 토큰을 발급받아야 하는건지 이해불가...)
이제는 메서드들을 이용해 본격적으로 자동화를 시켜보자. 나의 task 는 다음과 같다
1. 내가 가진 대시보드 4개의 필터 200개를 돌려 pdf 로 다운받기
2. 대시보드의 항목 중 null 값이 있는 경우에는 pdf 생성에서 제외시키기
3. 만들어진 네 개의 pdf 를 합치고
4. 4월보고서_필터이름 이라는 조건으로 이름을 지정해 저장하기
1. 서버에 연결하기
이 코드를 이용하면 연결이 가능하다
Response 200 이 뜨면 연결이 잘 됐다는 뜻이다
conn = TableauServerConnection(config_json=config, env='tableau_prod')
conn.sign_in()
2. 대시보드 정보 (id) 가져오기
겟 뷰를 이용해서 대시보드 정보를 가져올 수 있다. (정보 보안 문제로 보여주긴 어려우나) 가져온 데이터프레임의 'id' 컬럼에 들어와있는 아이가 각 대시보드의 고유 id 가 된다. 뒤에서 쓸거니 잘 메모해두자
views_df = querying.get_views_dataframe(conn)
views_df.tail()
3. id 를 이용해 필터링하기
3.1. 가지고 올 대시보드 아이디를 지정한다
3.2. 반복문으로 돌릴 리스트를 만들고, 저장경로를 지정한다
3.3. 필터 이름과 필터에 들어갈 value 를 파싱해준다. 이때! 필터 이름이 너무 길고 한국어로 되어있으면 파싱값이 지저분하게 나오고, 에러날 확률이 올라감. 참고!!
3.4. 파라미터를 지정해준다. 레이아웃 뷰랑 아까 파싱한 필터를 지정하면 된다.
3.5. response 값이 200인 경우만 (에러가 아닌 경우만) pdf 로 추출한다
#가지고 올 대시보드 아이디
pdf_view_id = 'put your dashboard id'
#반복문으로 돌아갈 항목 리스트
li = df['user_nickname'].tolist()
#저장경로지정
output_dir = '/content/drive/MyDrive/somewheref'
#필터링 할 대상 지정
import urllib
import os
for i in li:
#파싱
#url_friendly 하게 입력값을 바꿔주는것임
filter_name = urllib.parse.quote("Nickname")
filter_value = urllib.parse.quote(i)
#필터링 지정
pdf_params = {
"pdf_orientation":"orientation=Landscape",
"pdf_layout":"type=A4",
"name_filter": f"vf_{filter_name}={filter_value}",
}
zero_pdf = conn.query_view_pdf(view_id = pdf_view_id , parameter_dict= pdf_params)
if zero_pdf.status_code == 200:
output_filename = f"0.{i}.pdf"
output_path = os.path.join(output_dir, output_filename)
with open(output_path, 'wb') as file:
file.write(zero_pdf.content)
else:
print(f"{i} 누락")
나의 경우에는 일단 따로따로 항목별로 저장해 준 뒤 합쳤다
이중포문을 쓰니 에러가 심했음...
4. pdf 로 합치기
pdf merger 를 이용했다.
버젼때문에 오류가 잦음...
이부분은 지피티의 도움을 받았음.
from PyPDF2 import PdfReader, PdfMerger
import os
output_dir = 'something'
# Loop through the image pairs
# Open the two images for this pair
pdf1 = open(f'something {i}).pdf', 'rb')
pdf2 = open(f'something {i}).pdf', 'rb')
pdf3 = open(f'something {i}).pdf', 'rb')
# Create a PDF merger object
pdf_merger = PdfMerger()
# Add the three PDF files to the merger object
pdf_merger.append(PdfReader(pdf1))
pdf_merger.append(PdfReader(pdf2))
pdf_merger.append(PdfReader(pdf3))
# Get the user name for the current image pair
for name, number in user_dict.items():
if str(number) == str(i):
user_name = name
break
# Construct the output filename
output_filename = f'_유저분석보고서_{user_name}.pdf'
pdf_merger.write(os.path.join(output_dir, output_filename))
참조
https://www.youtube.com/watch?v=b8QElp-qV7w&t=870s
https://www.youtube.com/watch?v=yYo-TyqG_Ks
'데이터 분석 Data Analysis > Tableau' 카테고리의 다른 글
| [태블로] 태블로 월별로 여러 데이터셋 집계하기 (0) | 2023.09.03 |
|---|---|
| [태블로] 태블로 데이터 refresh 하는 법 3가지 (0) | 2023.08.31 |
| [태블로] 태블로 날짜 월별로 예쁘게 나타내기 (jan, feb, mar...) (0) | 2023.08.21 |