앞선 글에서 살펴본 시계열 데이터는 데이터 통계의 가장 기본적인 가정인 등분산성도, 자기상관성도, 정상성도 파괴해 버리는 특이한 데이터라는 점을 알 수 있다. 이런 데이터들의 경우 전통적인 머신러닝 기법들인 ARIMA 시리즈에 데이터를 집어넣기 어렵기 때문에 우리는 이 데이터들의 특수성을 제거해준 뒤 머신러닝에 넣어줄 필요가 있는데, 이때 주로 사용하는 방법들은 다음과 같다
1. 차분 (differencing)
데이터를 차분한다는것은 t 시점과 t-1 시점의 값의 차이를 구하는 것이다
쉽게 말하면, 데이터를 차분하면 우리는 데이터의 변동값을 알게 되어 데이터의 앞뒤에 받았던 영향을 제거하고 랜덤한 데이터만으로 머신러닝 예측을 할 수 있는 것이다.
차분을 수학 공식으로 나타내면 다음과 같다

이때, 차분하는 데이터의 가장 첫 번째 값은 뺄 수 있는 직전값이 없기 때문에 변동값을 구하지 못하게 된다. 따라서 데이터를 차분하게 되면 t-1 개의 데이터를 결과적으로 얻을 수 있다.
다음은 구글 주식 가격 데이터이다. 왼쪽은 차분하기 전의 데이터 (추세성이 있기 때문에 정상성을 띈다고 보기 어렵다) 이고, 오른쪽은 차분 한 후의 데이터이다.
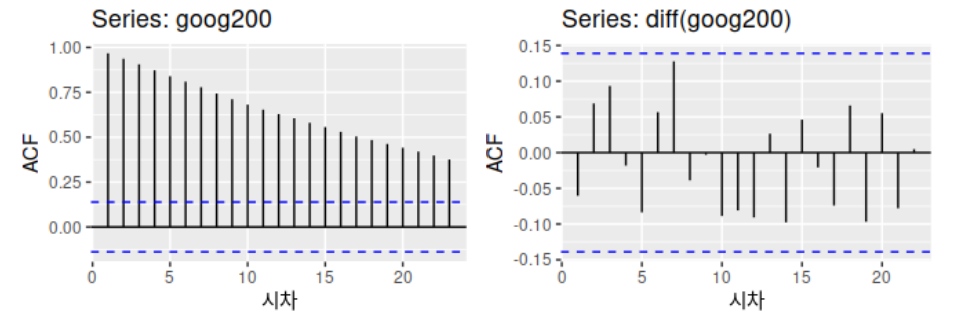
차분 후의 데이터는 완전이 지난 장에서 다뤘던 백색소음(white noise) 같은 형태의 데이터로 바뀌게 된다. 이렇듯 우리는 차분을 통해 완전히 random 한 variation 의 데이터를 뽑아낼 수 있다. (앞의 데이터와의 상관성이 없는 데이터라고 가정하고 분석할 수 있게 된다)
*때로 한 번의 차분으로도 여전히 정상성을 띄지 않아 두번, 세번 차분을 하는 경우도 있다
2. 로그 변환
로그 변환은 시계열 데이터 뿐만 아니라 그냥 데이터의 variation 이 너무 커서 분석이 어려운 데이터에 자주 씌워준다. 특히 데이터의 분산이 큰 경우 고려할 수 있는 방법이며, 이는 데이터가 가지는 전반적인 range 를 줄여주는 원리인데, 그림으로 알아보기 위해 필자의 다음 게시물을 참조하도록 하자.
https://datasciencefromsebi.tistory.com/12
데이터분석에서 로그를 취하는 경우 (세상에서 제일 쉬운 설명)
우리는 가끔.... (이 아니라 사실 자주) 괴이한 데이터를 만난다. 가령 우리의 데이터는 이렇게 생길 수도 있다 ....? 혹은 이럴지도 모른다 ............? 실로 괴이한 현상이 아닐 수가 없다. 이는 내
datasciencefromsebi.tistory.com
3. 로그변환 + 차분
보통의 데이터 전처리에서는 로그 변환을 먼저 실행시켜주는 것이 대부분이다. 로그 변환을 통해 분산을 안정화 시킨 후, 차분을 통해 데이터가 정상성을 띄게끔 바꿔주는 것이다. 비슷한 예시로 시계열이 아닌 데이터를 전처리할때, 로그 변환 후 scaler 를 적용하는 일반적인 방법을 떠올리면 이해가 더 쉬울 것 같다.
4. 정상성을 띄는 나의 데이터
그렇게 변환이 완료된 나의 데이터는 (드디어) 머신러닝에 넣을 수 있는 정상성을 띄게 된다. 이를 확인할 수 있는 방법은 통상적으로 두가지가 있는데, 하나는 그래프의 모양을 보고 눈대중으로 체크하는 방법, 하나는 수치를 통해 확인하는 방법이다.
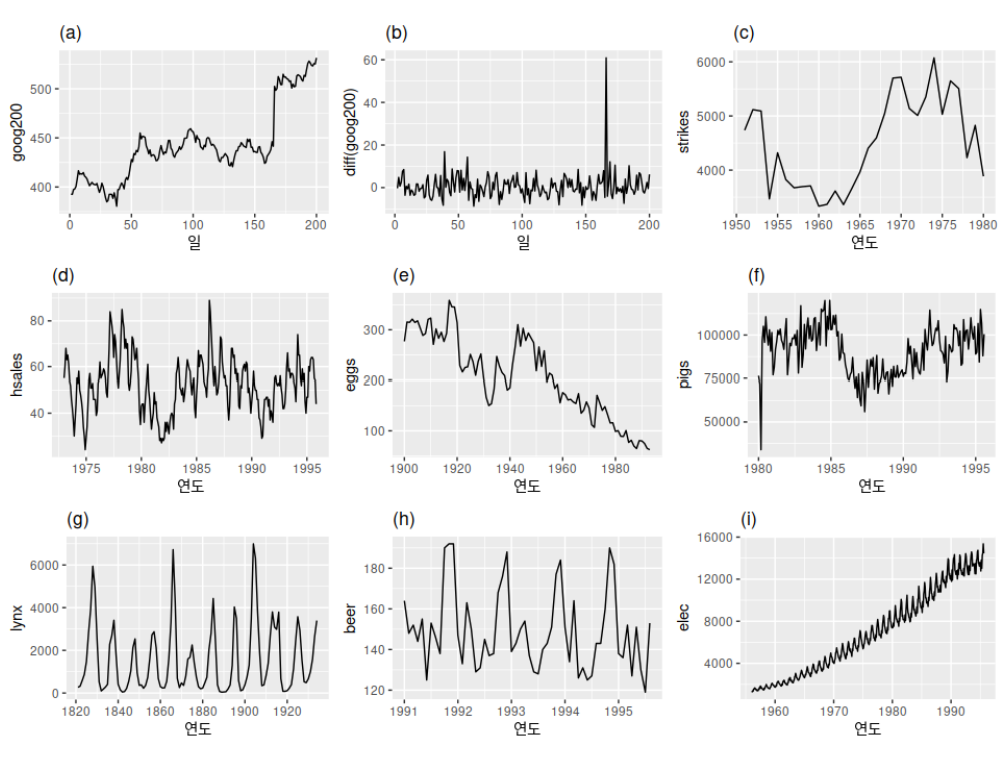
먼저 전자의 방식, "눈대중으로 보는 방법" 을 설명하겠다. 앞선 게시글의 이 표에서는 b 와 g 만이 정상성을 띄는 데이터라고 했다. 추세성, 계절성 등이 제거되었는지, 분산의 변동폭은 어떠한지 그래프를 시각화해 본다면 눈으로 쉽게 확인할 수 있다
다음으로 두 번째 방법 "수치를 통해 확인하는 법" 을 설명하겠다
1, 자기 상관 함수 (ACF; Auto Correlation Function): 데이터를 차분한 값이 ACF 의 범주 안에 들어오면 정상성을 띈 데이터라고 생각할 수 있다
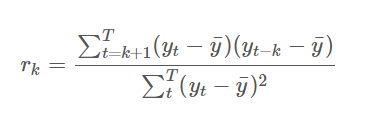
이 복잡한 수식을 이해하진 않아도 되고, 다만 시각화를 했을 때 신뢰구간 안에 들어오는지 눈으로만 확인하면 된다. 이는 차후에 다른 포스팅으로 더욱 상세하게 짚고 넘어가겠다
2. Dicky Fuller test
시계열 데이터는 안정적이지 않다는 귀무가설에 p-value 가 0.05 를 넘으면 채택하는 일반적인 방법을 따른다.
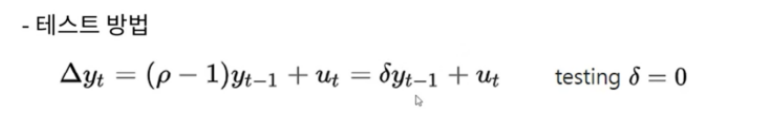
다음 장에서는 다양한 시계열 모형의 개요들을 알아보자
'데이터 과학 Data Science > 시계열 데이터' 카테고리의 다른 글
| [시계열] 일반 머신러닝 모델로 시계열 데이터 돌리는 법 (0) | 2023.05.24 |
|---|---|
| [시계열] 시계열 모델 기초(1) 안정시계열 -AR , MA , ARMA (세상에서 제일 쉬운 설명) (0) | 2023.03.09 |
| [시계열] 시계열 모델들의 종류와 경우에 따른 시계열 모델 선정법 (0) | 2023.03.06 |
| [시계열] 시계열 데이터의 특징들 -1. 자기상관성, 정상성, 등분산성 (1) | 2023.03.03 |