시계열 데이터라 함은 단순히 시간 순으로 나누어진 데이터다. 그런데, 시게열 데이터에는 계절성이라던가, 반복성, 순환성, 추세성 같은 특징들이 있다. 저런 특이한 성질들이나 추세 때문에 시계열 데이터에서는 저 성질을 제외하고 머신러닝에 넣어주는 작업이 굉장히 중요하다.
왜일까? 예를 들어 보겠다.
자 가장 쉬운 예시를 가져왔다. 다음은 우유 생산량으로 시계열 데이터의 계절성 (seasonality) 를 확인할 수 있는 그래프다. 부패하기 쉬운 여름에 생산량이 확 줄었다가 봄가을에 다시 많아지는 계절성을 보인다. 이런 데이터의 range 의 variousity 를 머신러닝에 집어넣으면 머신러닝은 이를 포착하지 못하기 때문에 어느정도의 bias 가 생기기 마련이다.

위 그래프는 전반적으로 우상향 그래프를 그리고 있으나 이 안에는 random 하게 분포되어있는게 아니라 그 안에서 어떤 특정한 패턴을 가지고 있다. 그래서 데이터 통계의 가장 기본적인 원칙인 "자기상관성" 에 어긋나기 때문에 패턴을 없애주는 것이 선실행 되어야 한다는 것이다.
기본적인 원칙?
데이터를 다룰 때 우리가 기본적으로 인지해야하는 데이터들의 가정에 대해 먼저 한번 짚고 넘어가보자
1. 자기상관성 (Autocorelation) : 횡단면 데이터는 기본적으로 각각 독립적이라는 가정을 가진다
-> 내가 가져온 데이터셋에 "아파트 가격" 에 대한 열과 "주택 가격" 에 대한 열 두 가지가 있는 경우, 그래 우리는 직관적으로 저 둘이 어떤 상관성을 가진다는걸 알겠지만 숫자만 놓고 봤을때는 두 데이터는 독립적이라는 가정 하에 분석을 진행해야 한다
그런데 시계열 데이터는 이 자기상관성을 파괴시켜버린다! 기본적으로 시계열 데이터는 데이터 포인트 하나하나가 앞 뒤 포인트의 데이터에 매우 밀접한 영향을 주기 때문이다.
즉, 데이터가 독립적이지 않고 상관성이 뚜렷하게 드러나기 때문에 바로 일반적인 모델 안에 넣어주면 안되는 것이다.
2. 정상성 (stationary) : 늘 한결같고 일정한 데이터가 정상성을 띈 데이터다
-> 특정한 주기에 따라 움직이는 계절성도 있으면 안되고, 우상향 하는 추세성도 있으면 안된다, 또한 분산도 일정해야 한다.
그렇다면 위 그래프 중 어떤 데이터가 정상성을 띈 데이터일까?
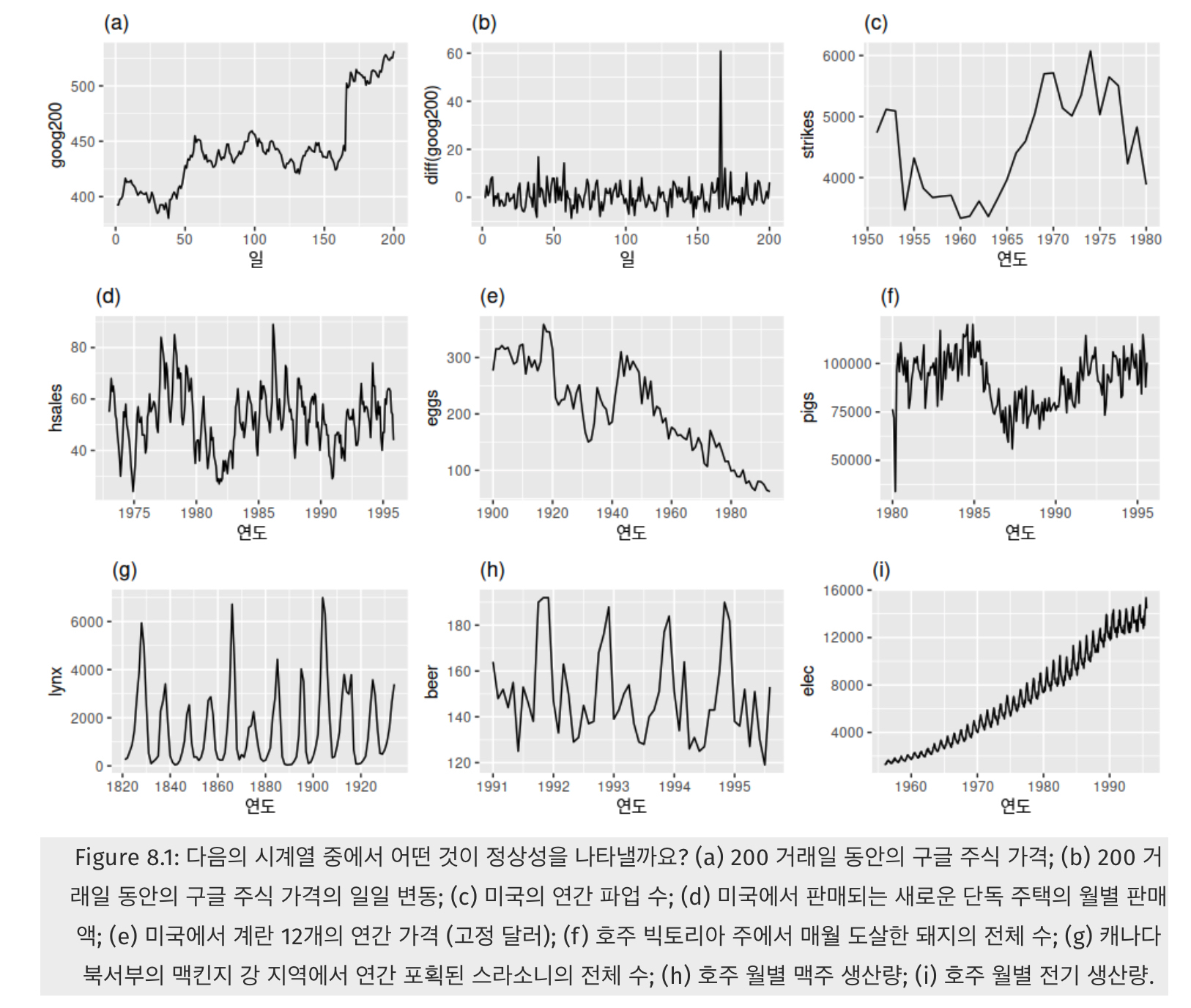
위 그림에서는 b 와 g 가 정상성을 띈 데이터다.
i 는 계속해서 분산이 커지기 때문에, a,c, f,e 는 추세성이 있기 때문에, h 와 d 는 계절성이 있기 때문에 정상성이 없는 데이터이다.
뭐 여하튼! 그래프를 봐서 알겠지만 대부분의 시계열 데이터는 이 정상성 역시 따르지 않는다! 시간에 따라 너무 많은 random 한 사건들이 일어나고, 데이터가 변화할 위험이 너무 크기 때문이다. 때문에 우리는 비정상성을띈 데이터를 정상성을 띈 데이터로 바꿔주어야 한다
3. 등분산성 (Homoscedasticy) : 등분산성은 분산이 비슷비슷한 성질을 말한다
-> 변수의 variation 이 점점 커지거나 작아지거나 random 한 경우가 등분산성을 띄지 않는 경우다.

위 그림에서 왼쪽은 등분산성을 띈 경우, 오른쪽은 그렇지 않은 경우다. 오른쪽 데이터들이 시간에 따라 더 널리 퍼지는 모습을 보이며 분산이 커진다.
따라서... 시계열 데이터는 이래서 어려운 것이다.
자기상관성도, 정상성도, 등분산성도 만족하지 못하는, 데이터 통계에서 기본적으로 만족해야 하는 세 가지 속성을 모두 파괴해버리는 데이터를 만나기 때문에, 이 성질을 바꿔줄 수 있는 뭔가의 작업 (차분 혹은 log 치기) 를 해 주어야 하는 것이다
그래서! 이 모든 변동성들을 제거하고 나면,
아무런 구조적인 패턴이 보이지 않는, 그저 변화들이 백색소음의 우연변동이라고 말할 수 있는 데이터로 바꿔줄 수 있게 된다
이렇게 데이터를 바꿔주고 나서 머신러닝에 넣어주는 것이 시계열 데이터에서 높은 예측률을 위해 반드시 해야 하는 전처리 작업이다
다음 시간에는 데이터에 로그를 치고 차분을 하는 방법들에 대해 알아보겠다
참조 : https://assaeunji.github.io/statistics/2021-08-08-stationarity/
패스트캠퍼스 기업강의
'데이터 과학 Data Science > 시계열 데이터' 카테고리의 다른 글
| [시계열] 일반 머신러닝 모델로 시계열 데이터 돌리는 법 (0) | 2023.05.24 |
|---|---|
| [시계열] 시계열 모델 기초(1) 안정시계열 -AR , MA , ARMA (세상에서 제일 쉬운 설명) (0) | 2023.03.09 |
| [시계열] 시계열 모델들의 종류와 경우에 따른 시계열 모델 선정법 (0) | 2023.03.06 |
| [시계열] 시계열 데이터의 전처리 - 차분, 로그변환, ACF (0) | 2023.03.06 |
시계열 데이터라 함은 단순히 시간 순으로 나누어진 데이터다. 그런데, 시게열 데이터에는 계절성이라던가, 반복성, 순환성, 추세성 같은 특징들이 있다. 저런 특이한 성질들이나 추세 때문에 시계열 데이터에서는 저 성질을 제외하고 머신러닝에 넣어주는 작업이 굉장히 중요하다.
왜일까? 예를 들어 보겠다.
자 가장 쉬운 예시를 가져왔다. 다음은 우유 생산량으로 시계열 데이터의 계절성 (seasonality) 를 확인할 수 있는 그래프다. 부패하기 쉬운 여름에 생산량이 확 줄었다가 봄가을에 다시 많아지는 계절성을 보인다. 이런 데이터의 range 의 variousity 를 머신러닝에 집어넣으면 머신러닝은 이를 포착하지 못하기 때문에 어느정도의 bias 가 생기기 마련이다.
위 그래프는 전반적으로 우상향 그래프를 그리고 있으나 이 안에는 random 하게 분포되어있는게 아니라 그 안에서 어떤 특정한 패턴을 가지고 있다. 그래서 데이터 통계의 가장 기본적인 원칙인 "자기상관성" 에 어긋나기 때문에 패턴을 없애주는 것이 선실행 되어야 한다는 것이다.
기본적인 원칙?
데이터를 다룰 때 우리가 기본적으로 인지해야하는 데이터들의 가정에 대해 먼저 한번 짚고 넘어가보자
1. 자기상관성 (Autocorelation) : 횡단면 데이터는 기본적으로 각각 독립적이라는 가정을 가진다
-> 내가 가져온 데이터셋에 "아파트 가격" 에 대한 열과 "주택 가격" 에 대한 열 두 가지가 있는 경우, 그래 우리는 직관적으로 저 둘이 어떤 상관성을 가진다는걸 알겠지만 숫자만 놓고 봤을때는 두 데이터는 독립적이라는 가정 하에 분석을 진행해야 한다
그런데 시계열 데이터는 이 자기상관성을 파괴시켜버린다! 기본적으로 시계열 데이터는 데이터 포인트 하나하나가 앞 뒤 포인트의 데이터에 매우 밀접한 영향을 주기 때문이다.
즉, 데이터가 독립적이지 않고 상관성이 뚜렷하게 드러나기 때문에 바로 일반적인 모델 안에 넣어주면 안되는 것이다.
2. 정상성 (stationary) : 늘 한결같고 일정한 데이터가 정상성을 띈 데이터다
-> 특정한 주기에 따라 움직이는 계절성도 있으면 안되고, 우상향 하는 추세성도 있으면 안된다, 또한 분산도 일정해야 한다.
그렇다면 위 그래프 중 어떤 데이터가 정상성을 띈 데이터일까?
위 그림에서는 b 와 g 가 정상성을 띈 데이터다.
i 는 계속해서 분산이 커지기 때문에, a,c, f,e 는 추세성이 있기 때문에, h 와 d 는 계절성이 있기 때문에 정상성이 없는 데이터이다.
뭐 여하튼! 그래프를 봐서 알겠지만 대부분의 시계열 데이터는 이 정상성 역시 따르지 않는다! 시간에 따라 너무 많은 random 한 사건들이 일어나고, 데이터가 변화할 위험이 너무 크기 때문이다. 때문에 우리는 비정상성을띈 데이터를 정상성을 띈 데이터로 바꿔주어야 한다
3. 등분산성 (Homoscedasticy) : 등분산성은 분산이 비슷비슷한 성질을 말한다
-> 변수의 variation 이 점점 커지거나 작아지거나 random 한 경우가 등분산성을 띄지 않는 경우다.
위 그림에서 왼쪽은 등분산성을 띈 경우, 오른쪽은 그렇지 않은 경우다. 오른쪽 데이터들이 시간에 따라 더 널리 퍼지는 모습을 보이며 분산이 커진다.
따라서... 시계열 데이터는 이래서 어려운 것이다.
자기상관성도, 정상성도, 등분산성도 만족하지 못하는, 데이터 통계에서 기본적으로 만족해야 하는 세 가지 속성을 모두 파괴해버리는 데이터를 만나기 때문에, 이 성질을 바꿔줄 수 있는 뭔가의 작업 (차분 혹은 log 치기) 를 해 주어야 하는 것이다
그래서! 이 모든 변동성들을 제거하고 나면,
아무런 구조적인 패턴이 보이지 않는, 그저 변화들이 백색소음의 우연변동이라고 말할 수 있는 데이터로 바꿔줄 수 있게 된다
이렇게 데이터를 바꿔주고 나서 머신러닝에 넣어주는 것이 시계열 데이터에서 높은 예측률을 위해 반드시 해야 하는 전처리 작업이다
다음 시간에는 데이터에 로그를 치고 차분을 하는 방법들에 대해 알아보겠다
참조 : https://assaeunji.github.io/statistics/2021-08-08-stationarity/
패스트캠퍼스 기업강의
'데이터 과학 Data Science > 시계열 데이터' 카테고리의 다른 글
| [시계열] 일반 머신러닝 모델로 시계열 데이터 돌리는 법 (0) | 2023.05.24 |
|---|---|
| [시계열] 시계열 모델 기초(1) 안정시계열 -AR , MA , ARMA (세상에서 제일 쉬운 설명) (0) | 2023.03.09 |
| [시계열] 시계열 모델들의 종류와 경우에 따른 시계열 모델 선정법 (0) | 2023.03.06 |
| [시계열] 시계열 데이터의 전처리 - 차분, 로그변환, ACF (0) | 2023.03.06 |