유사도 전파... Affinity Propagation 이라고 부르는데, 데이터 사이언스 웹사이트나 교재에 자주 소개되는 대표적인 비지도학습 클러스터링 방법 중 하나다. 공부해 보니 구현 방법이 상당히 독특하고 사용하는 case 도 특이해. 근데 국내에서 많이 안 쓰는지 한국어로 된 자료가 정말 별로 없더라.. 난 특이한걸 좋아하니깐 포스팅해보도록 하겠다.
1. 작동 원리
일단 유사도 전파는 쉽게 설명하면 각각의 데이터셋 포인트들 하나하나가 자기를 대표해 줄 만한 데이터에 투표를 하는 방식임! 데이터들 간의 유사성을 기준으로 자기랑 비슷하고 대표성이 있다고 판단되는 데이터에 대표투표를 해주고, (메시지를 전달한다 ~ 이렇게도 표현함) 최적의 대표 집합에 수렴할때까지 알고리즘이 반복한다
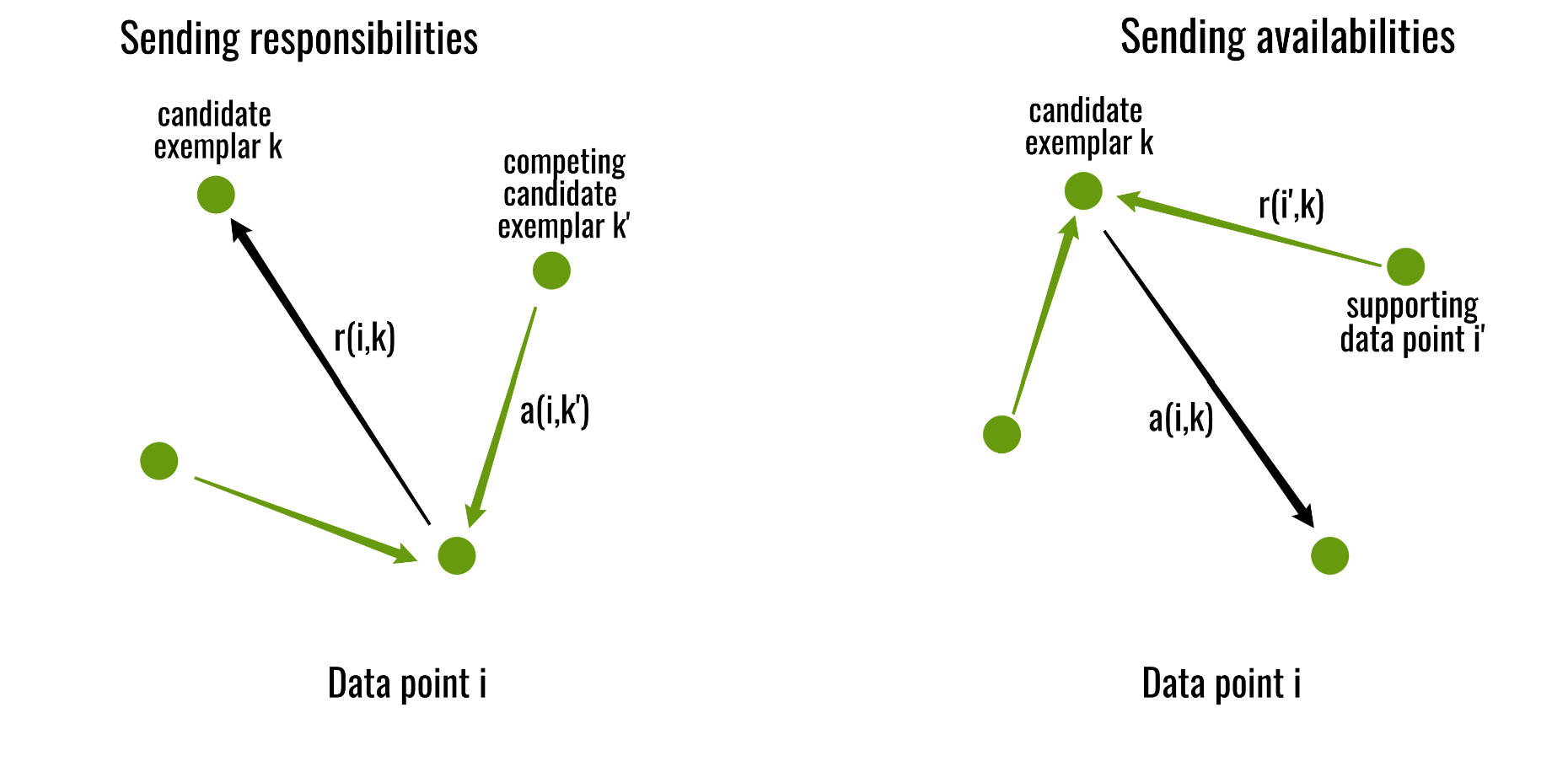
당연히 투표는 수식을 이용해서 하는데요...ㅋㅋㅋ
- 두 점 사이 유사도 Similarity Matrix
- 대표성을 나타내는 Responsibility Matrix
- 클러스터의 중심으로서의 가치가 있는지 판단하는 Availability Matrix
이렇게 세 가지를 어찌어찌 구해서 합니다.
난 수식 설명 못 하겠으니 궁금하면 여기 들어가서 읽어보자
2. 다른 모델들과의 차이점
수식을 세가지나 쓰잖아요.. 시간복잡도 공간복잡도 모두 높은 아이다. 데이터셋의 단위가 작은 경우에만 쓸 수 있고, k 값을 사전에 안 정해줘도 됨. 근데 이거 말고는 딱히 눈에 보이는 특징이나 장점이 없어서 안 쓸거같긴 해.. 구현 방법이 특히하다는거 빼고...ㅎㅎ 내갘 이미 해외자료 한 10개 뒤져보ㅓ써 장점이 안 뜬다니깐??? this algorithm needs improvement 이런거나 나와요
3. 예제코드
다른건 똑같아요 주의할건 preference 옵션인데 저게 커질수록 클러스터가 많아짐..
여기 이분이 저거 조절하면서 실험해보셨는데 적당한 값을 찾기가 어려운거같애
코드는 진짜 저게 다임.. 데이터 그냥 넣어주면 됩니다
af = AffinityPropagation(preference=-50)
clustering = af.fit(X)흠... 잘 안 쓸듯...ㅎㅎㅎㅎ
'데이터 과학 Data Science > 비지도학습' 카테고리의 다른 글
| 계층적 클러스터링 (0) | 2022.10.18 |
|---|---|
| DBSCAN으로 클러스터링 (1) | 2022.10.04 |
| 가우시안 혼합 모델로 클러스터링 (1) | 2022.09.19 |
| 평균 이동 알고리즘으로 데이터 클러스터링 (1) | 2022.09.19 |
| k-means 알고리즘으로 패턴 찾고 평가까지 (0) | 2022.09.18 |