1. 개요
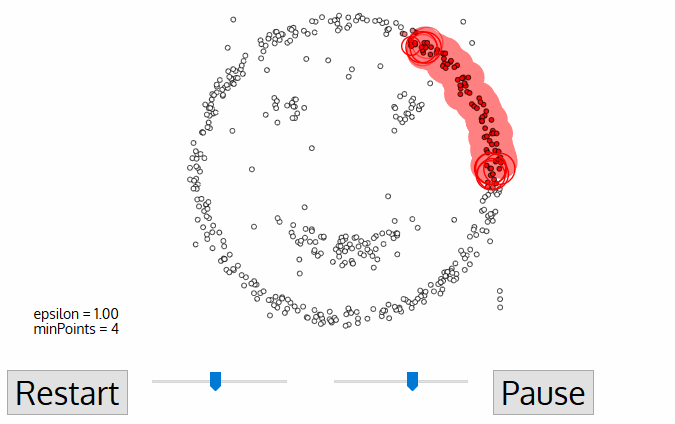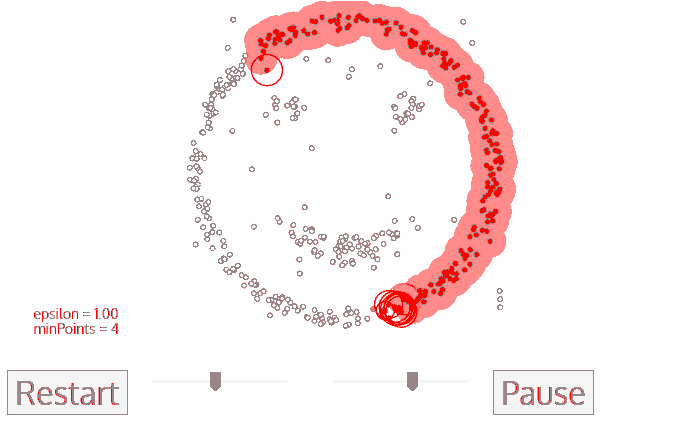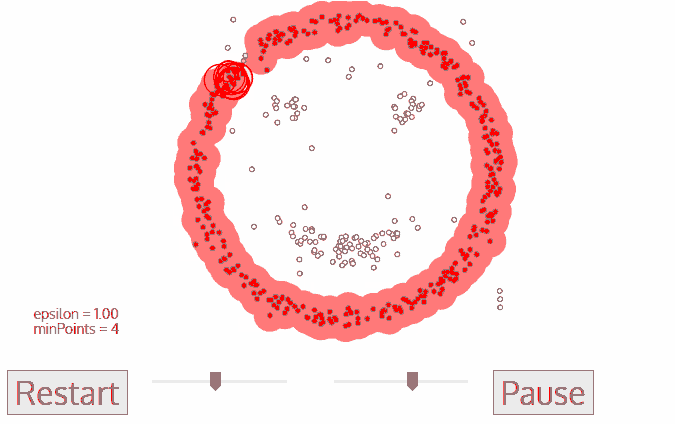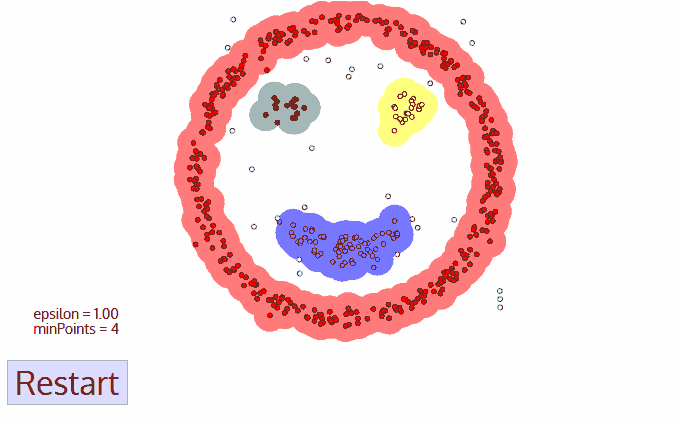
DBSCAN 은 아주 강력한 클러스터링 방식으로 알려져있다! 제일 대표적으로 거론되는 k-means clustering 과의 차이를 먼저 언급해보자면, 클러스터의 개수를 정해야 할 필요가 없고, 이상치 탐지에 최고인 방식인 점이다. 이상치가 많은 경우 DBSCAN 을 쓰는게 k-means 보다는 유리한데, 그 이유는 DBSCAN 은 노이즈를 분류하기 때문이다. K-means 는 평균으로부터 좀 떨어져 있는 데이터이더라도 반드시 그 데이터를 어떤 집단에 넣는 반면, DBSCAN 은 탐색 반경으로부터 먼 데이터는 노이즈라고 분류한다.
이 그림을 보자

DBSCAN 은 "더 잘 연결된" 데이터를 하나의 클러스터로, k-means는 "거리가 가까운" 데이터를 하나의 클러스터로 취급한다. 이런 이유 때문에 실무에서 제일 많이 쓰이는 클러스터링 방법 중 하나가 DBSCAN 이라고 하는데, 그 이유는 k-means 의 경우 어떤 집단으로부터 딱히 비슷하지도 않은 데이터를 "그나마 가깝다" 는 이유만으로 그 집단에 넣어버리기 때문이라고 한다. (극단적인 경우 이상치가 centroid 를 자기 자신으로 끌고오는 경우도 있다고 한다....)
결국 하나의 클러스터가 표현해주는 속성의 정도가 약해질 뿐만 아니라, 최적의 집단 개수를 모를 때는 k-means 를 쓰는게 불리한 선택이 되는 것이다.
2. 작동 방법
A. 데이터셋 전체에서 밀집 지역을 찾고, 그 지역 내에서 어떤 점을 Core Point 로 지정
B. 어떤 데이터에서 eps 안의 거리값 안에 들어오는 것들은 클러스터 내의 값으로 지정한다. 그런데, 이 과정에서 min-samples 파라미터 값보다 설정된 값이 작다면 값들은 모두 noise 로 처리된다.
C. eps 안의 포인트가 없을때까지 반복한다

3. 소스코드
라이브러리 import
from sklearn.cluster import DBSCAN
import numpy as np
샘플코드 생성
X = np.array([[1, 2], [2, 2], [2, 3],[8, 7], [8, 8], [25, 80]])
모델 선언, 필수 파라미터 지정
eps = 탐색반경
min_samples = 클러스터 내 최소 데이터
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering.labels_
#out: array([ 0, 0, 0, 1, 1, -1])
예측
clusters = DBSCAN.fit_predict(X)
print('클러스터 레이블:\n', clusters)
https://colab.research.google.com/drive/1j4VS5CoZ928WS0ZPFQyc1MMfmcBfX6eh?usp=sharing
'데이터 과학 Data Science > 비지도학습' 카테고리의 다른 글
| 계층적 클러스터링 (0) | 2022.10.18 |
|---|---|
| 유사도 전파 Affinity Propagation 모델로 클러스터링 (1) | 2022.09.20 |
| 가우시안 혼합 모델로 클러스터링 (1) | 2022.09.19 |
| 평균 이동 알고리즘으로 데이터 클러스터링 (1) | 2022.09.19 |
| k-means 알고리즘으로 패턴 찾고 평가까지 (0) | 2022.09.18 |
1. 개요
DBSCAN 은 아주 강력한 클러스터링 방식으로 알려져있다! 제일 대표적으로 거론되는 k-means clustering 과의 차이를 먼저 언급해보자면, 클러스터의 개수를 정해야 할 필요가 없고, 이상치 탐지에 최고인 방식인 점이다. 이상치가 많은 경우 DBSCAN 을 쓰는게 k-means 보다는 유리한데, 그 이유는 DBSCAN 은 노이즈를 분류하기 때문이다. K-means 는 평균으로부터 좀 떨어져 있는 데이터이더라도 반드시 그 데이터를 어떤 집단에 넣는 반면, DBSCAN 은 탐색 반경으로부터 먼 데이터는 노이즈라고 분류한다.
이 그림을 보자
DBSCAN 은 "더 잘 연결된" 데이터를 하나의 클러스터로, k-means는 "거리가 가까운" 데이터를 하나의 클러스터로 취급한다. 이런 이유 때문에 실무에서 제일 많이 쓰이는 클러스터링 방법 중 하나가 DBSCAN 이라고 하는데, 그 이유는 k-means 의 경우 어떤 집단으로부터 딱히 비슷하지도 않은 데이터를 "그나마 가깝다" 는 이유만으로 그 집단에 넣어버리기 때문이라고 한다. (극단적인 경우 이상치가 centroid 를 자기 자신으로 끌고오는 경우도 있다고 한다....)
결국 하나의 클러스터가 표현해주는 속성의 정도가 약해질 뿐만 아니라, 최적의 집단 개수를 모를 때는 k-means 를 쓰는게 불리한 선택이 되는 것이다.
2. 작동 방법
A. 데이터셋 전체에서 밀집 지역을 찾고, 그 지역 내에서 어떤 점을 Core Point 로 지정
B. 어떤 데이터에서 eps 안의 거리값 안에 들어오는 것들은 클러스터 내의 값으로 지정한다. 그런데, 이 과정에서 min-samples 파라미터 값보다 설정된 값이 작다면 값들은 모두 noise 로 처리된다.
C. eps 안의 포인트가 없을때까지 반복한다
3. 소스코드
라이브러리 import
from sklearn.cluster import DBSCAN
import numpy as np
샘플코드 생성
X = np.array([[1, 2], [2, 2], [2, 3],[8, 7], [8, 8], [25, 80]])
모델 선언, 필수 파라미터 지정
eps = 탐색반경
min_samples = 클러스터 내 최소 데이터
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering.labels_
#out: array([ 0, 0, 0, 1, 1, -1])
예측
clusters = DBSCAN.fit_predict(X)
print('클러스터 레이블:\n', clusters)
https://colab.research.google.com/drive/1j4VS5CoZ928WS0ZPFQyc1MMfmcBfX6eh?usp=sharing
'데이터 과학 Data Science > 비지도학습' 카테고리의 다른 글
| 계층적 클러스터링 (0) | 2022.10.18 |
|---|---|
| 유사도 전파 Affinity Propagation 모델로 클러스터링 (1) | 2022.09.20 |
| 가우시안 혼합 모델로 클러스터링 (1) | 2022.09.19 |
| 평균 이동 알고리즘으로 데이터 클러스터링 (1) | 2022.09.19 |
| k-means 알고리즘으로 패턴 찾고 평가까지 (0) | 2022.09.18 |